프로젝트의 빌드과정을 조금 더 쉽게 해주는 것이지요. 그렇다고 해서 이클립스가 빌드 툴이냐? 하면 그것은 아닙니다. 이클립스의 경우는 IDE입니다. 즉 메이븐은 빌드과정에 대해 특화 시킨 것이 메이븐입니다.
MAVEN처럼 빌드를 도와주는 빌드 툴은 Gradle, Ant등이 있습니다.
Ant와는 어떠한 차이점이 있을까요?
Ant와 같은 툴은 전적으로 전처리(preprocessing), 컴파일(compilation), 패키징(packaging), 테스팅(testing), 배포(distribution)하는데 초점이 잘 맞추어져 있다.
메이븐과 같은 프로젝트 관리 툴은 빌드 툴을 바탕으로 여러 기능을 종합적으로 제공한다.
메이븐은 빌드에 관한 기능들과 보고서 작성, 웹사이트 생성, 작업 팀의 구성원 간 소통 기능을 제공한다.
메이븐 활용 패턴
1. build
소스 코드를 컴파일 한다
테스트 코드를 컴파일 한다
기타 패키지 생성을 위한 바이너리를 생성한다
2. Package
배포 가능한 jar, war, exe 파일 등을 생성한다
3. Test
단위 테스트(Unit, Test)등을 실행한다
빌드 결과가 정상인지 점검한다
4. Report
빌드/패키지/테스트 결과를 정리하고, 빌드 수행 리포트를 생성한다.
5. Release
빌드 후 생성된 아티팩트(artifact)를 로컬 혹은 원격 저장소에 저장(배포)한다.
메이븐의 주요 개념
1. Plugin
메이븐(Maven)은 플러그인 실행 프레임워크이다.
메이븐의 플러그인 메커니즘에 의해 기능이 확장된다. (모든 작업은 플러그인이 수행한다.)
사용자 관점에서는 앤트(Ant)의 태스트(Task)혹은 타겟(Target, 정확히 일치하지 않음)과 유사하다.
플러그인은 다른 산출물(artifacts)와 같이 저장소에서 관리된다.
플러그인은 goal의 집합이다.
2. LifeCycle
메이븐의 동작 방식은 일련의 단계(phase)에 연계된 goal을 실행하는 것이며, 논리적인 작업 흐름인 단ㄱ의 집합이 라이프사이클이다 ( 빌드단계<build phases>들은 사전 정의된 순서대로 실행되고 모든 빌드 단계는 이전 단계가 성공적으로 실행되었을 때, 실행된다)
빌드 단계는 goal들로 구성된다( goal은 특정 작업, 최소한의 실행단위이다. 각 단계는 0개 이상의 goal과 연관된다.)
메이븐은 3개의 표준 라이프사이클을 제공한다
1. cealn: 빌드 시 생성되었던 산출물을 지운다.
2. default: 일반적인 빌드 프로세서를 위한 모델
3. site : 프로젝트 문서와 사이트 작성을 수행한다.
내장 라이프 사이클
<default 라이프 사이클>
<clean 라이프사이클>
<site 라이프사이클>
의존성(dependency)
라이브러리 다운로드 자동화입니다. 더 이상 필요한(의존성 있는) 라이브러리를 하나씩 다운로드 받을 필요가 없습니다. 필요하다고 선언만 하면 메이븐이 자동으로 다운받아 줍니다.
메이븐은 선언적(명력식이 아니다): 사용되는 jar파일들을 어디서 다운로드 받고, 어느 릴리즈(버전)인지 명시하면, 코딩하지 않아도 메이븐이 알아서 관리합니다. (재 다운로드, 최신 버전 설치 등)
메이븐이 관리합니다. (라이브러리 디렉터리를 생성할 필요가 없습니다. 이클립스 내에서 라이브러리, 클래스패스 환경 설정을 할 필요도 없습니다.)
프로파일(profile)
서로 다른 대상 환경(target environment)를 위한 다른 빌드 설정 (다른 운영체제, 다른 배포 환경)
동작 방식(Activation) : -P 명령형 실행환경 옵션, 환경변수 기반
메이븐은 정상 절차(step) 이외에 프로파일을 위한 절차를 추가로 수행합니다.
POM(Project Object Model, 프로젝트 객체 모델)
프로젝트 당 하나의 pom.xml을 가집니다. pom은 프로젝트 자체와 의존성에 대한 설정 및 정보를 포함하고 메이븐을 pom.xml을 읽어, 프로젝트를 가공하는 방법을 이해합니다.
3가지 "coordinates"를 이용해 자원을 식별합니다
그룹 ID(Group ID)
아티팩트 ID(Artifact ID)
버전(Version)
POM 속성
<artifactId>
아티팩트의 명칭, groupId 범위 내에서 유일해야 합니다.
<groupId>
일반적으로 프로젝트의 패키지 명칭
<version>
아티팩트(artifact)의 현재 버전
<name>
어플리케이션의 명칭
<packaging>
아티팩트 패키지 유형, POM, jar, WAR, EAR, EJB, bundle, ....선택가능
<parent>
프로젝트의 계층 정보
<version>
아티팩트의 현재 버전
<scm>
소스 코드 관리 시스템 정보
<dependencyManagement>
의존성 처리에 대한 기본 설정 영역
<dependencies>
의존성 정의 및 설정 영역
CoC(Convention over Configuration)
메이븐의 큰 철학이며 명확한 '관습'으로 인해 더 편해진다는 의미입니다.
루비 온 레일스(Ruby on Rails)등으로 유명해졌습니다.
관습 혹은 기본 값은(Conventions, defaults)거의 다, 보이지 않는 "super pom"에 선언되어 있습니다.
그러나 인터넷 사용자가 폭발적으로 증가하고 애플리케이션의 기능이 복잡해짐에 따라 기존의 JDBC로 개발하는 데는 한계가 드러나게 되었습니다.
기존 JDBC로 개발할 경우 반복적으로 구현해야 할 SQL문도 많을 뿐만 아니라 SQL문도 복잡합니다. 따라서 자연스럽게 마이바티스나 하이버네이트 같은 데이터베이스 연동 관련 프레임워크가 등장하게 되었습니다.
기존의 JDBC를 연동하려면 다음과 같은 과정을 거쳐야 했습니다.
connection ->Statement 객체 생성 -> SQL문 전송 ->결과 반환 -> close
이방식의 단점은 SQL문이 프로그래밍 코드에 섞여 코드를 복잡하게 만든다는 것입니다. 이 방법을 개선해 SQL문의 가독성을 높여 사용하기 편하게 만든 것이 바로 마이바티스 프레임워크입니다.
마이바티스 프레임워크의 특징
SQL 실행 결과를 자바 빈즈 또는 Map 객체에 매핑해 주는 Persisitence 솔루션으로 관리합니다. 즉, SQL을 소스 코드가 아닌 XML로 분리합니다.
SQL문과 프로그래밍 코드를 분리해서 구현합니다.
데이터소스 기능과 트랜잭션 처리 기능을 제공합니다.
persistence framework의 구조
SqlMapConfig.xml에 각 기능별로 실행할 SQL문을 SqlMap.xml에 미리 작성한 후 등록합니다.
애플리케이션에서 데이터베이스와 연동하는데 필요한 데이터를 각각의 매개변수에 저장한 후 마이바티스에 전달합니다.
애플리케이션에서 요청한 SQL문을 SqlMap.xml에서 선택합니다.
전달한 매개변수와 선택한 SQL문을 결합합니다.
매개변수와 결합된 SQL문을 DBMS에서 실행합니다.
DBMS에서 반환된 데이터를 애플리케이션에서 제공하는 적당한 매개변수에 저장한 후 반환합니다.
다시 정리해 보자면 데이터베이스 연동 시 사용되는 SQL문을 미리 SqlMapConfig.xml에 작성해 놓고 애플리케이션에서 데이터 베이스 연동 시 해당 sql문에서 사용될 데이터를 지원하는 해당 매개 변수에 저장한 후 SQL문에 전달합니다. 전달된 매개변수와 SQL문을 결합해 SQL문을 DBMS로 전송하여 실행합니다. 그리고 그 결과를 애플리케이션에서 제공하는 자료형으로 반환합니다.
JDBC는 자바 데이터 접근 기술의 근간이라 할 정도로 대부분의 개발자가 쉽게 이해할 수 있어 많이 사용하는 데이터 액세스 기술입니다. 그러나 시간이 지남에 따라 SQL문이 지나치게 복잡해지면서 개발이나 유지관리에 어려움이 생기기 시작했습니다. 특히 cONNECTION 객체 같은 공유 리소스를 제대로 처리해주지 않으면 버그를 발생시키는 원인이 되곤 했습니다.
스프링에서 제공하는 JDBC는 이러한 기존 JDBC의 장점과 단순함을 유지하면서 단점을 보완했습니다. 간결한 API뿐만 아니라 확장된 JDBC의 기능도 제공합니다.
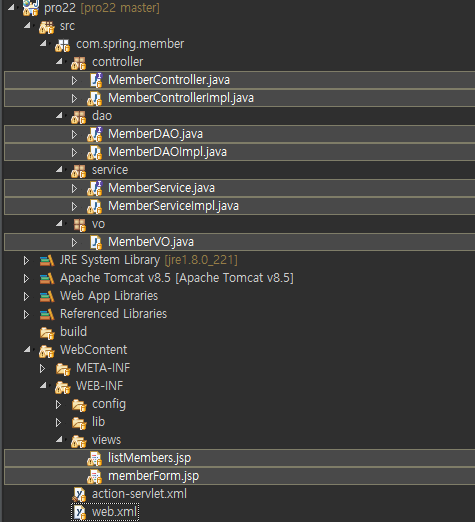
이번에 사용할 파일들 입니다.
lib 폴더와 action-servlet.xml , web.xml은 이 전글에서 했던 것들을 가져와 재사용 하겠습니다.
파일
설명
web.xml
ContextLoaderListener를 이용해 빈 설정 XML 파일들을 읽어 들입니다.
action-servlet.xml
스프링에서 필요한 여러 가지 빈을 설정합니다.
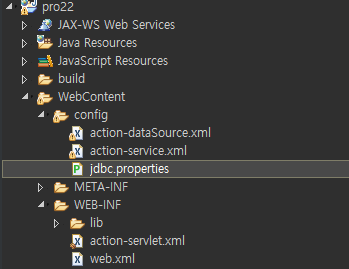
action-dataSource.xml
스프링 JDBC 설정에 필요한 정보를 설정합니다.
jdbc.properties
데이터베이스 연결정보를 저장합니다.
action-service.xml
서비스 빈 생성을 설정합니다.
1. action-servlet.xml과 action-dataSource.xml의 <beans> 태그는 이전 글에서 실습한 action-servlet.xml의 것을 복사해 붙여 넣겠습니다.
2. web.xml을 다음과 같이 작성합니다. 한 개의 XML 파일에서 모든 빈을 설정하면 복잡해서 관리하기 어려우므로 빈의 종류에 따라 XML 파일에 나누어 설정합니다. 그러면 톰캣 실행시 web.xml에서 스프링의 ContextLoaderListener를 이용해 빈 설정 XML 파일들을 읽어 들입니다.
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
id="WebApp_ID" version="3.1">
<!-- 여러 설정 파일을 읽어 들이기 위해 스프링의 ContextLoaderListener를 설정합니다. -->
<listener>
<listener-class>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
<!-- 애플리케이션 실행 시 ContextLoaderListener로 해당 위치의 설정 파일을 읽어 들입니다. -->
/WEB-INF/config/action-service.xml
/WEB-INF/config/action-dataSource.xml
</param-value>
</context-param>
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>org.springramework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
</web-app>
3. action-servlet.xml을 다음과 같이 작성합니다. 여기서는 뷰 관련 빈과 요청을 처리할 빈 그리고 메서드를 설정합니다. 이때 주의할 점은 빈 주입 시 주입 받는 클래스에서는 주입되는 빈에 대한 setter를 반드시 구현해야 한다는 것입니다.
5. 다음으로 action-dataSource.xml을 작성합니다. 이 파일은 스프링에서 사용할 데이터베이스 연동 정보를 설정합니다. 먼저 jdbc.properties 파일에서 데이터베이스 연결 정보를 가져온 후 이 연결 정보를 이용해 스프링에서 제공하는 SimpleDriverDataSource로 id가 dataSource인 빈을 생성합니다. 그리고 dataSource 빈을 memberDAO 빈으로 주입합니다.