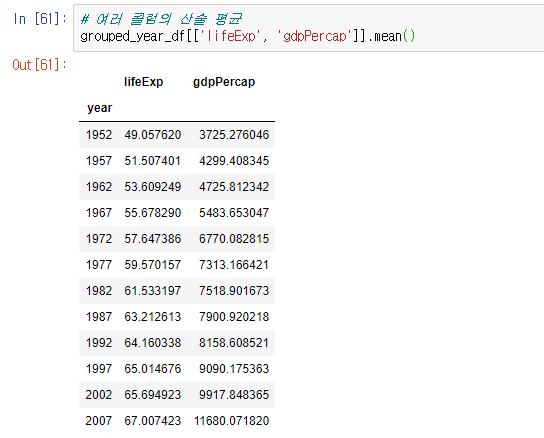
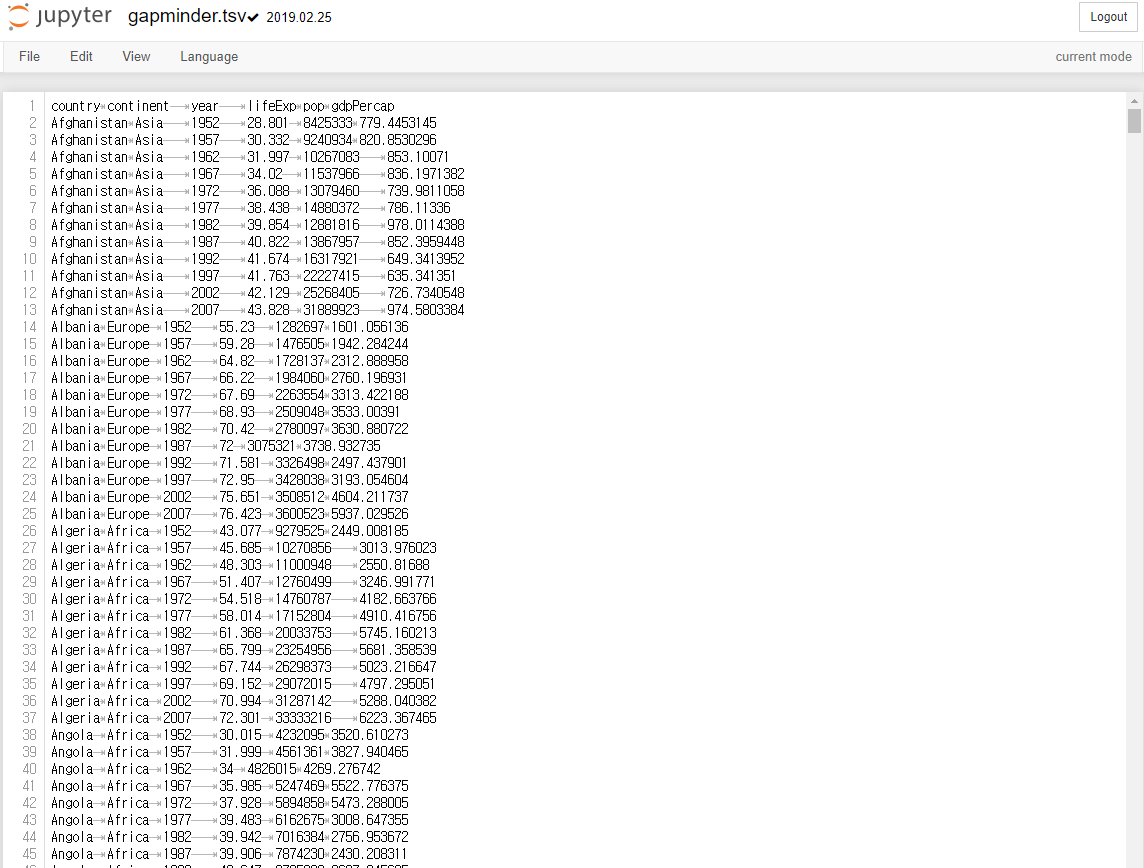
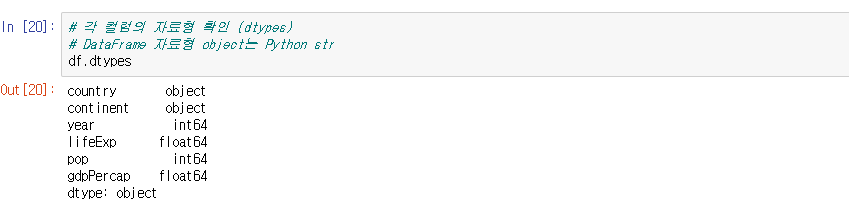
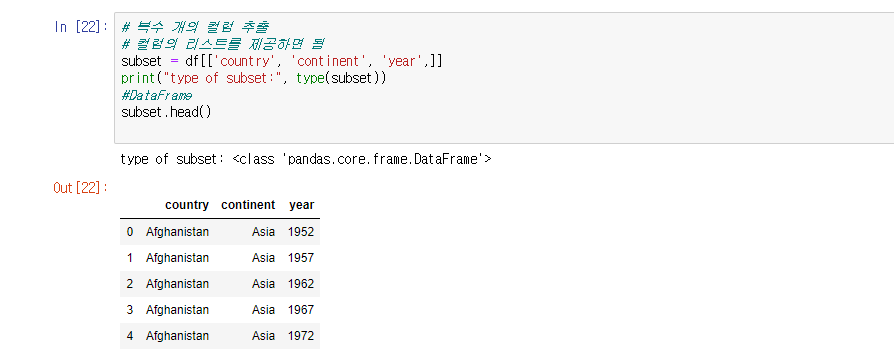
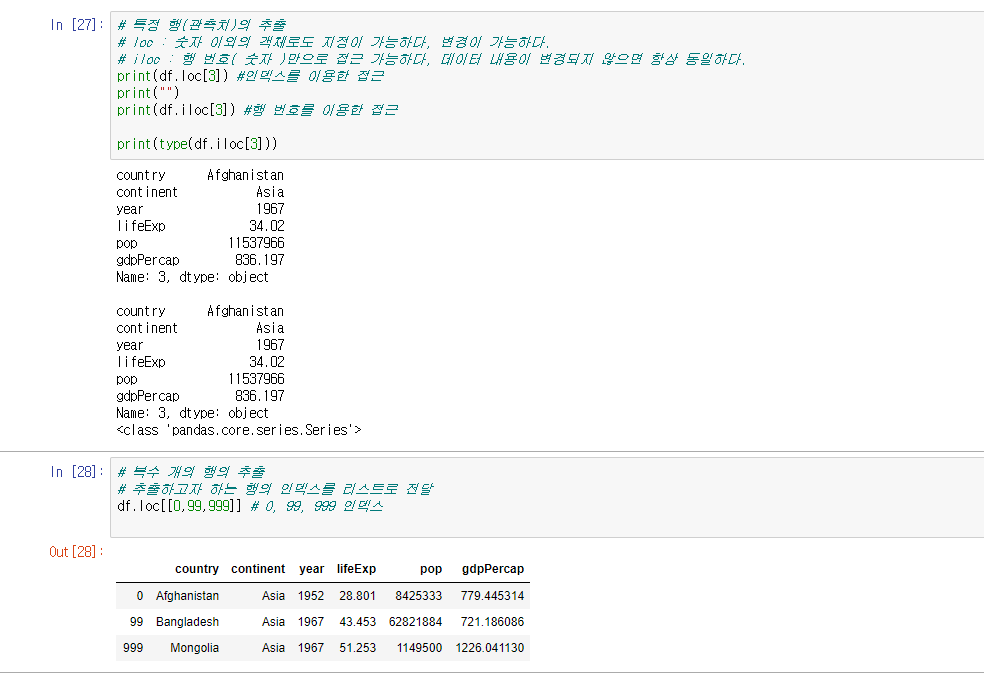
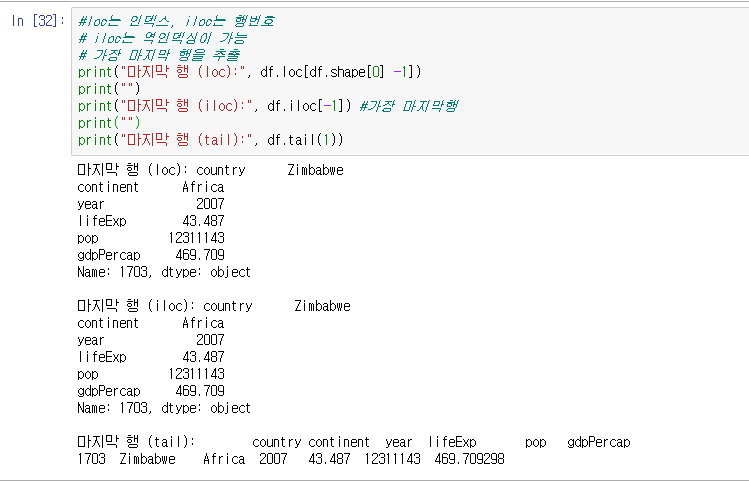
Python pandas anscombe(앤스콤) 4분할 그래프l, 그래프의 종류(histogram, boxplot, scatter, pie chart)
2020/Python 2019. 11. 28. 15:32반응형
아나콘다에는 seaborn이 있어서 따로 설치해주지 말고 import만 해주면 됩니다 (예전 anaconda는 없을 수도 있음)
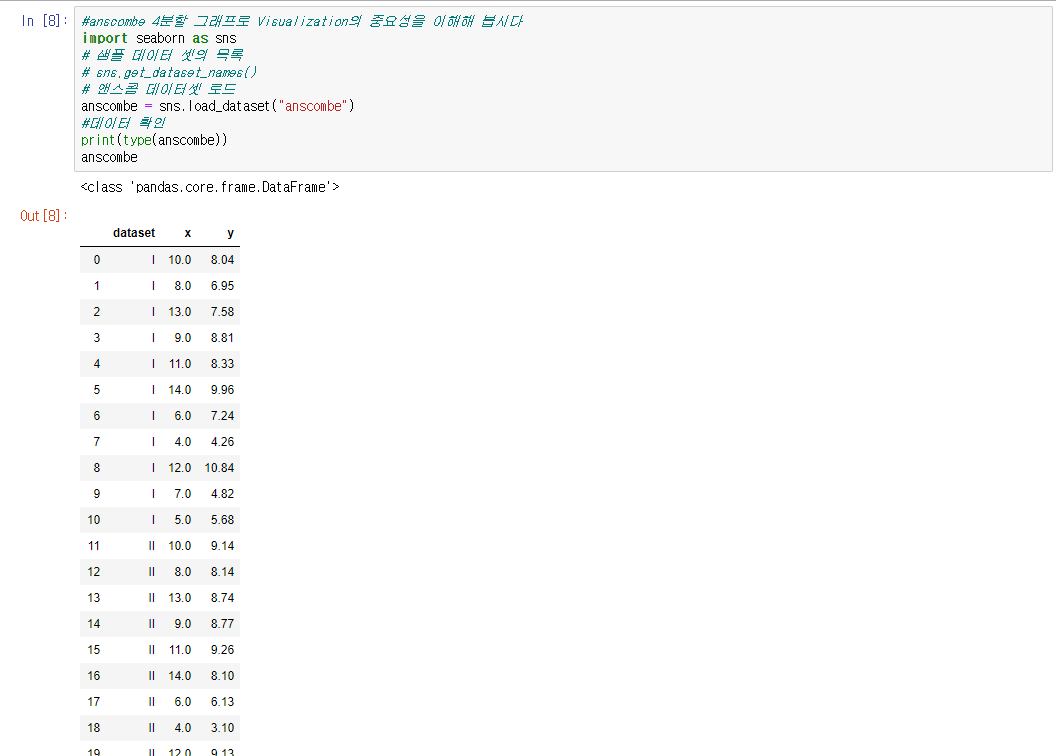
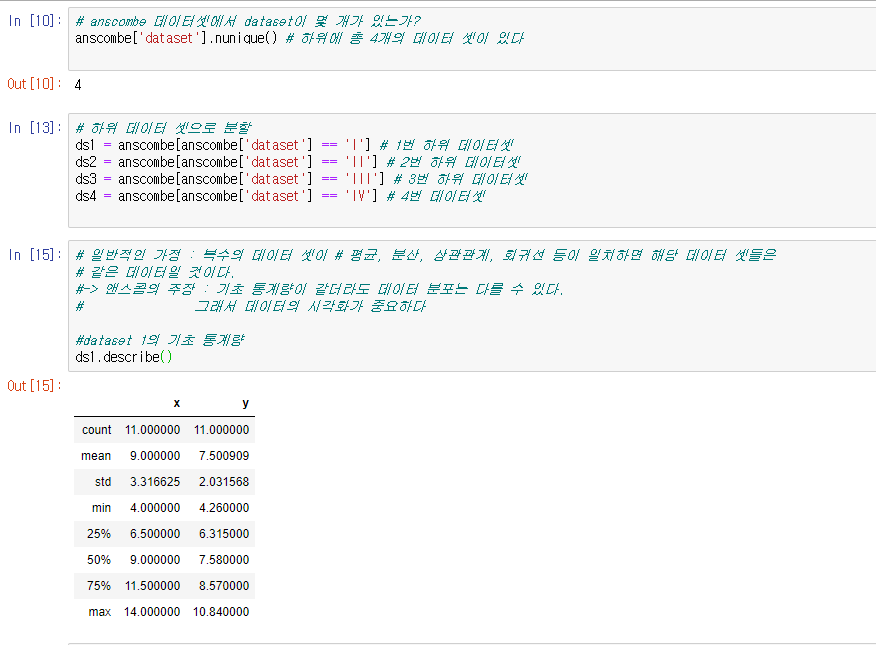

데이터를 시각화 해보도록 합니다.
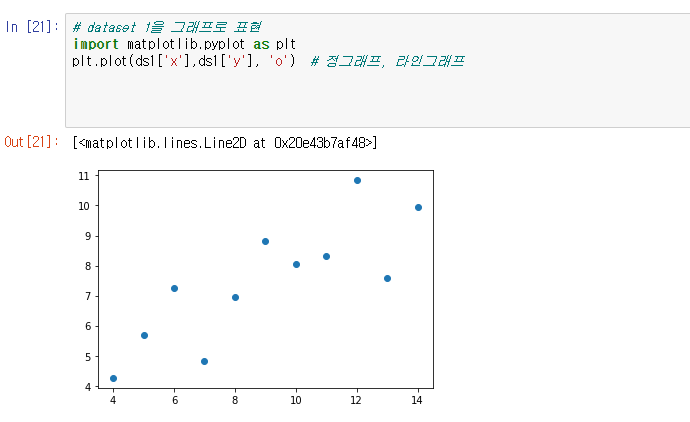
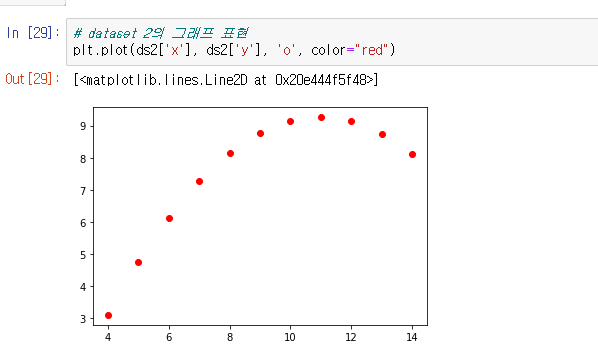
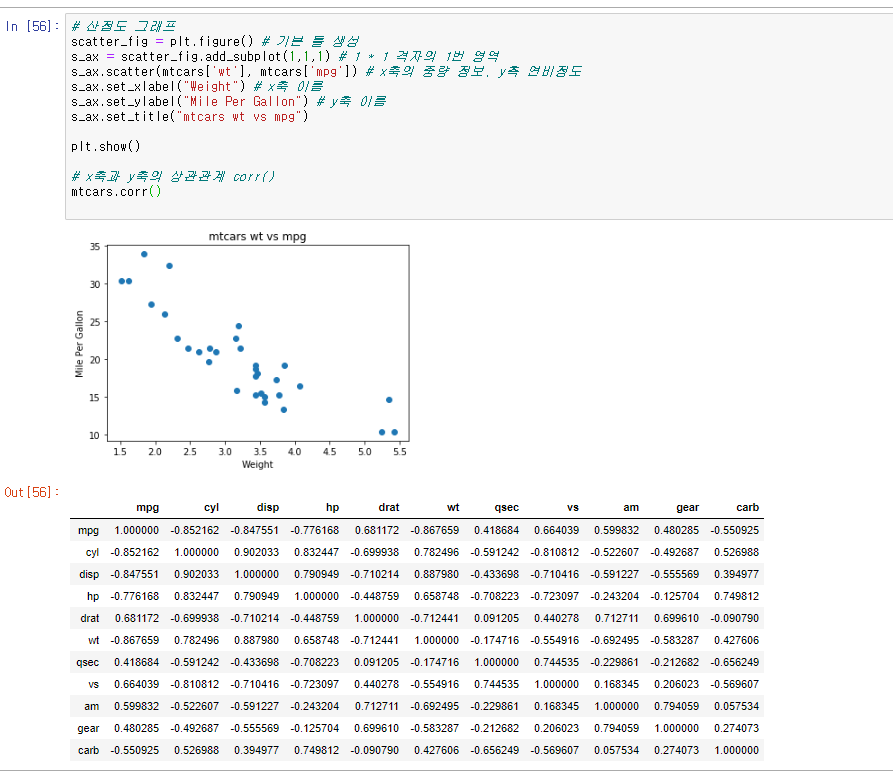
산점도 그래프
박스 그래프


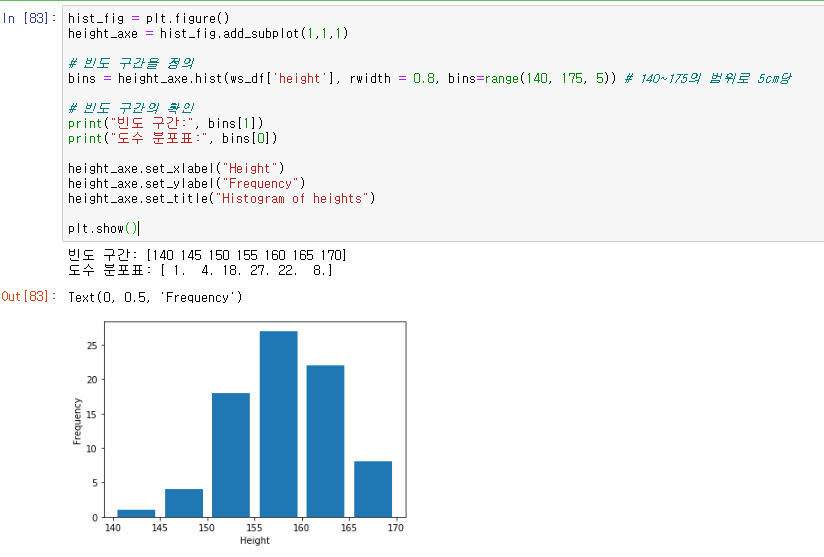
히스토그램

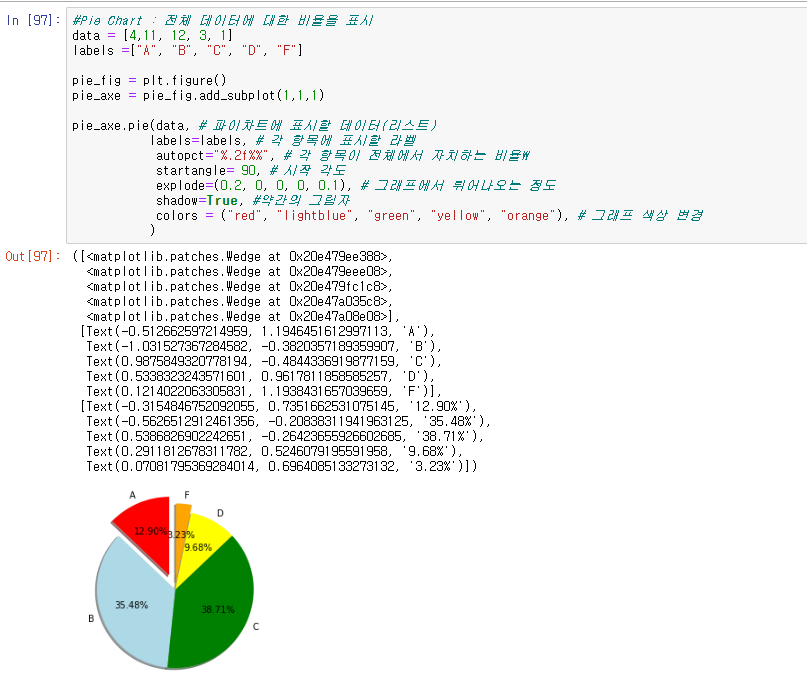
Pie chart
반응형
'2020 > Python' 카테고리의 다른 글
| Jupyter Notebook List형 (0) | 2019.12.10 |
|---|---|
| Jupyter Notebook 자료형 (0) | 2019.12.10 |
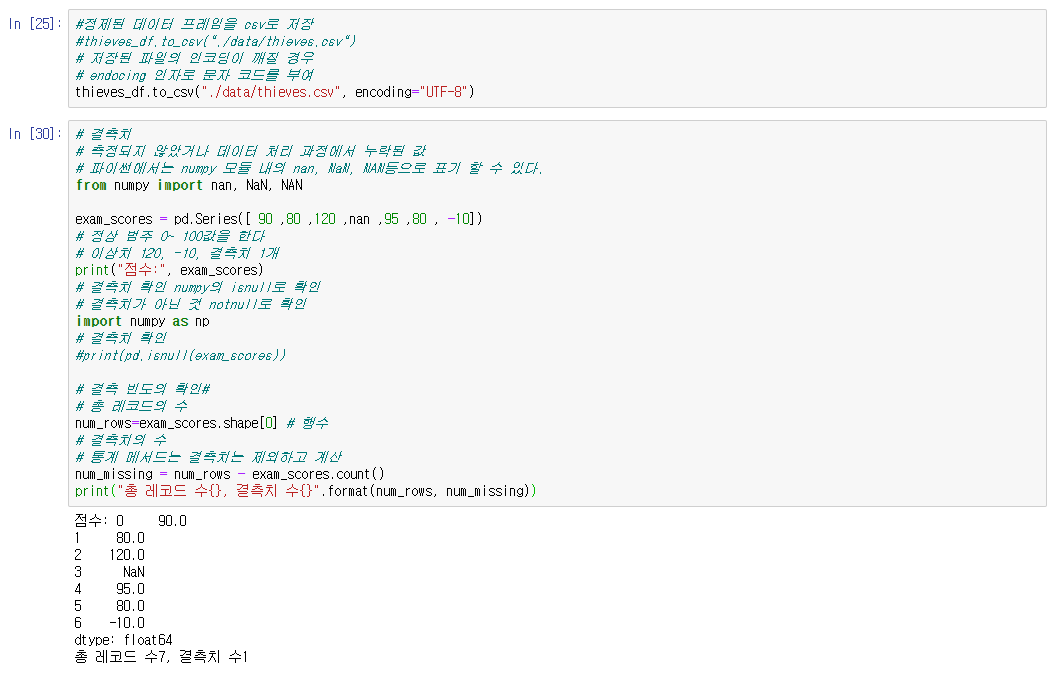
| Python (pandas) 결측치와 이상치 (0) | 2019.11.28 |
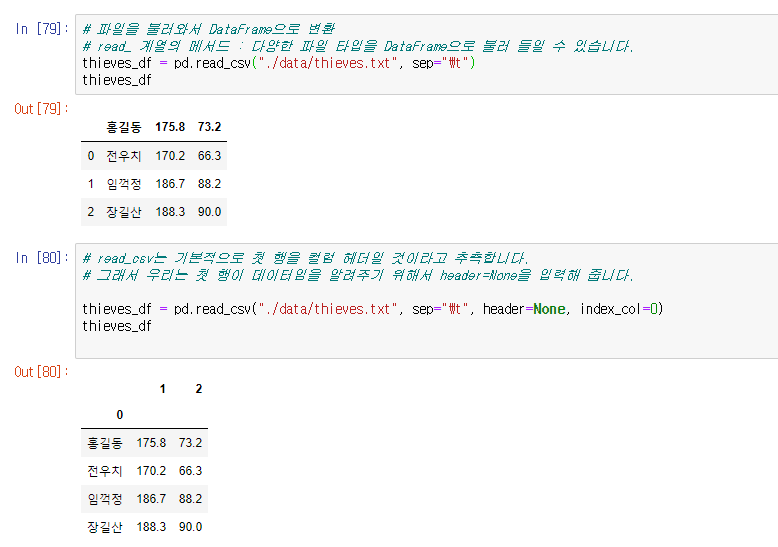
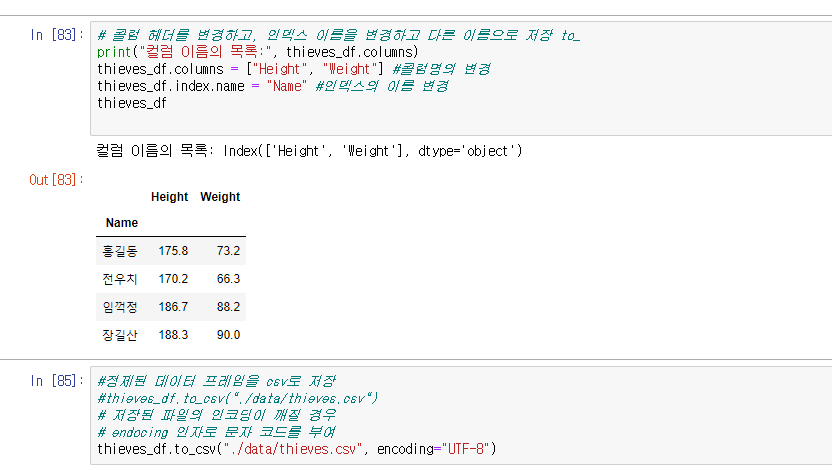
| Python(pandas) # 6 read_csv, header=None, index_col=0, 콜럼명 변경, 파일저장. (0) | 2019.11.28 |
| Python(pandas) # 5 DataFrame생성, 추출, 파생변수 생성 (0) | 2019.11.28 |

꽃꽂이하는개발자