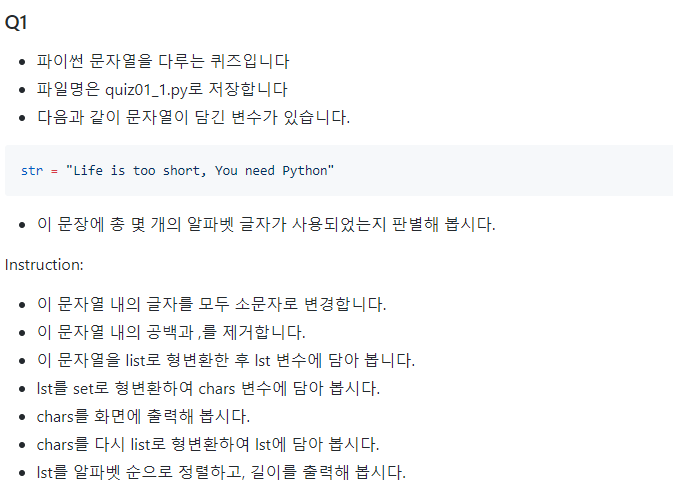
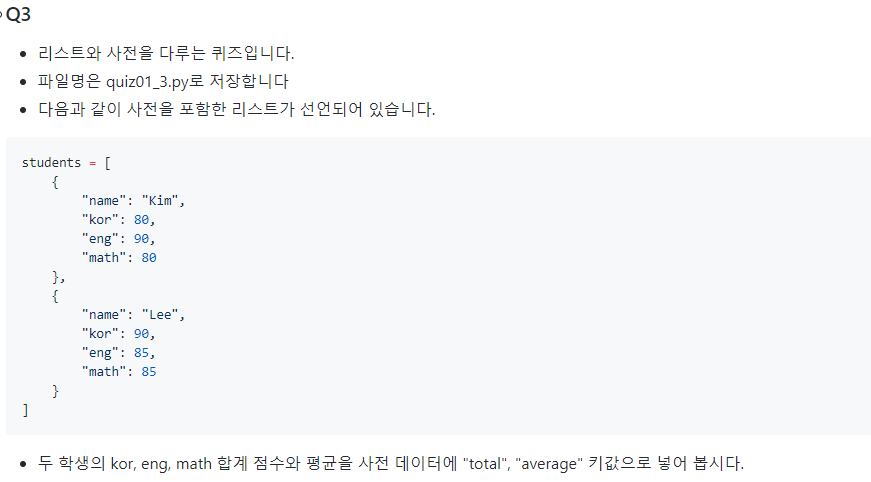
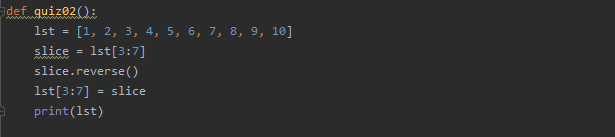
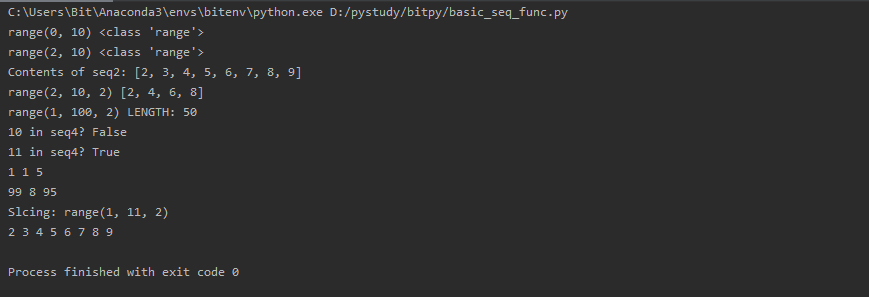
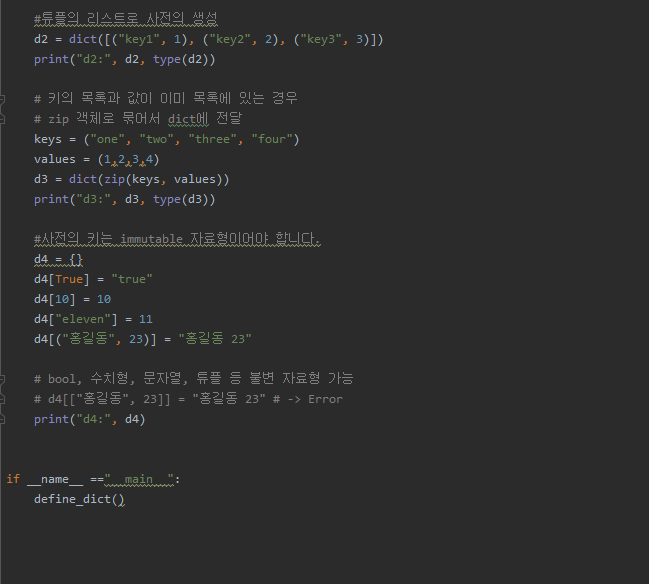
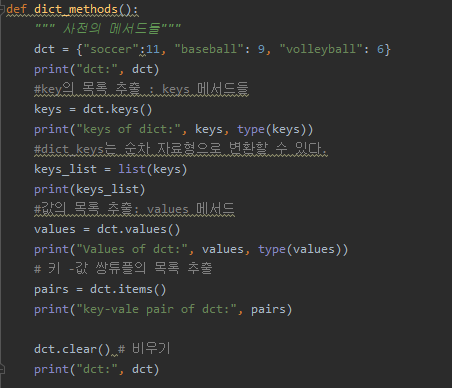
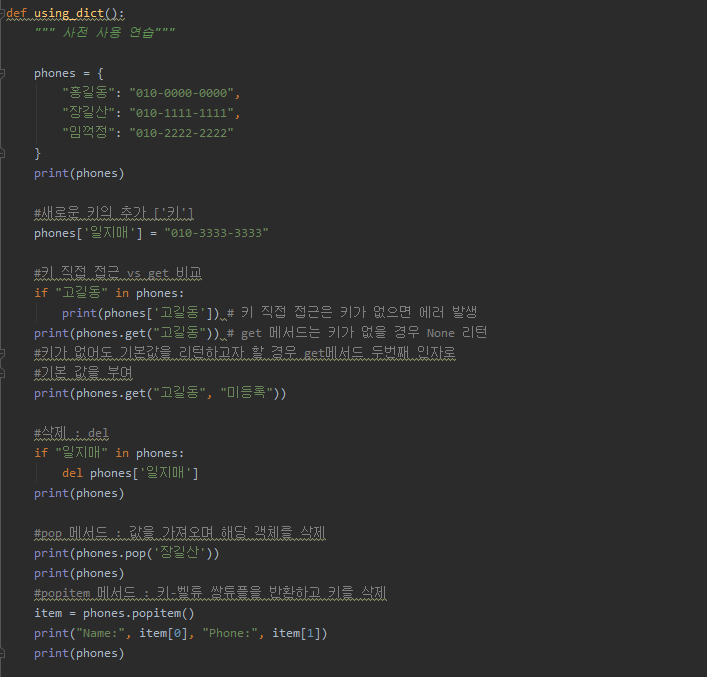
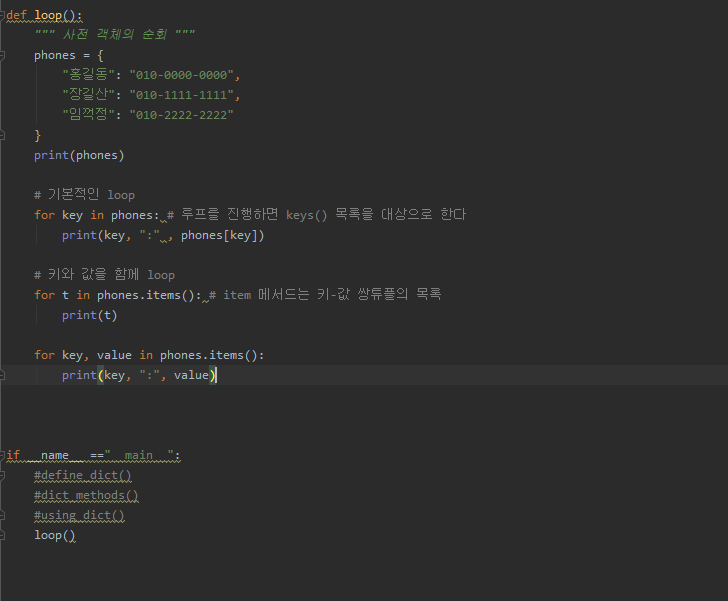
copy 는 일반적으로 복사라고 생각하면 됩니다.
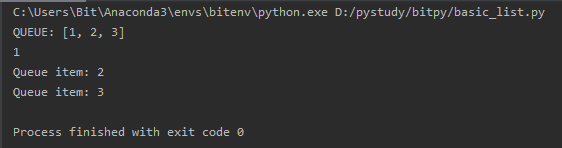
a= 1,2,3,4
b = a
여기서 b를 바꾸면 a또한 바뀝니다. b가 a의 주소를 가지고 있기 때문이죠
하지만 deepcopy 는 객체 자체를 복제합니다
a= 1,2,3,4
b= a
a가 지고 있는 1,2,3,4 와
b가 가지고 있는 1,2,3,4 는 저장 위치가 다릅니다. ex)집 주소가 다름, 건물이 다름, 지역이 다름
그렇기 때문에 b를 바꿔도 b의 내용이 바뀌는 것이지 a의 내용이 바뀌는 것이 아닙니다.
하나의 주소를 가지고 있느냐? = copy
주소가 다르냐? = deepcopy







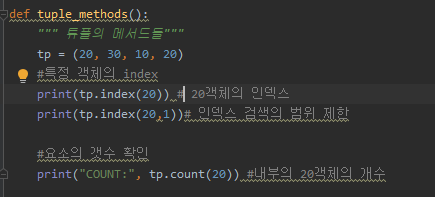
#객체의 이해
# 모듈 전체에서 공유되는 심벌들
g_a = 1 #글로벌 변수
g_b = "홍길동" #글로벌 변수
def func():
#내부에 로컬 심볼 영역이 생성
#객체에 접근할 경우, 로컬 영역 먼저 확인
#없을 경우 상위로 이동하여 검색합니다.
l_a = 2
l_b = "임꺽정"
# local 영역 심볼테이블 확인
print(locals())
class MyClass:
x = 10
y = 10
def symbol_table():
# 전역 변수 심볼 테이블 출력
print(globals())
print(type(globals()))
#dict로 반환
# 앞뒤에 __-> 심볼들은 파이썬 내부에서 사용하는 심볼. 변경하면 안된다
func()
#globals() 반환값이 dict
# 포함 여부 확인
print("g_a in global?", "g_a" in globals())
#내부에 __dict__ 를 확인하면 해당 객체 내부의 심볼 테이블 확인 가능
# 사용자 정의 함수 func의 심볼 테이블을 확인
print(func.__dict__)
print(MyClass.__dict__)
def object_id():
# 변수는 심볼명과 객체의 주소 값을 함께 가지고 관리된다
# id() 함수로 객체의 주소 확인
# is 연산자로 두 객체의 동질성을 확인할 수 있다
i1 = 10
i2 =int(10)
print("int:", hex(id(i1)), hex(id(i2)))
print(i1==i2)
print(id(i1) ==id(i2))
# 두 객체의 id() 값이 동일하다면 두 객체는 같은 객체
print(i1 is i2) # 두 객체가 동일 객체인지(같은 주소) 확인하는 연산자
# mutable 객체
lst1 = [1,2,3]
lst2 = [1,2,3]
print("lst1 == lst2 ?", lst1 == lst2) #동등성의 비교
print("lst1 is lst2 ?", lst1 is lst2) #is는 동일성의 비교
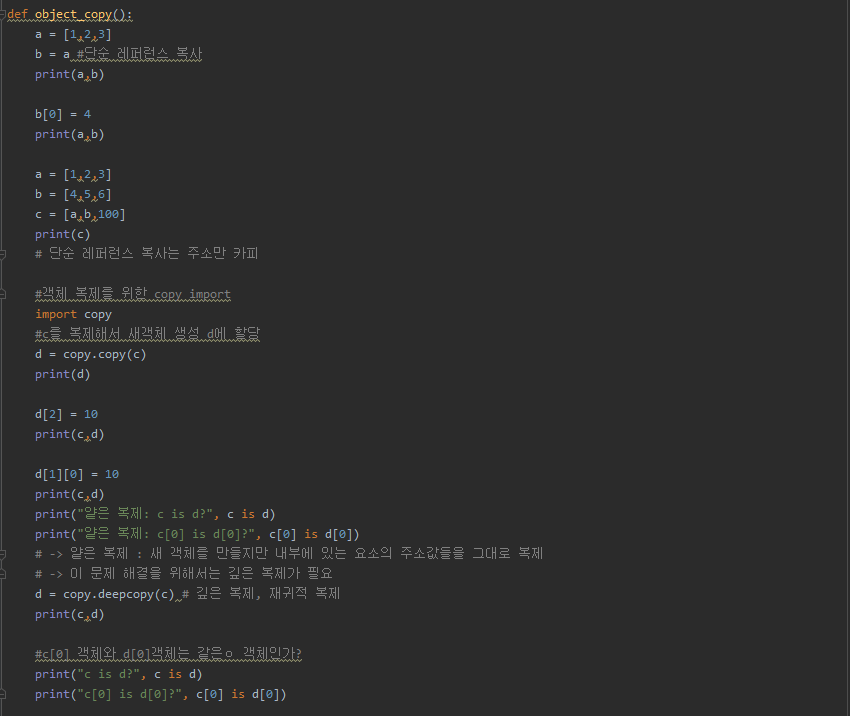
def object_copy():
a = [1,2,3]
b = a #단순 레퍼런스 복사
print(a,b)
b[0] = 4
print(a,b)
a = [1,2,3]
b = [4,5,6]
c = [a,b,100]
print(c)
# 단순 레퍼런스 복사는 주소만 카피
#객체 복제를 위한 copy import
import copy
#c를 복제해서 새객체 생성 d에 할당
d = copy.copy(c)
print(d)
d[2] = 10
print(c,d)
d[1][0] = 10
print(c,d)
print("얕은 복제: c is d?", c is d)
print("얕은 복제: c[0] is d[0]?", c[0] is d[0])
# -> 얕은 복제 : 새 객체를 만들지만 내부에 있는 요소의 주소값들을 그대로 복제
# -> 이 문제 해결을 위해서는 깊은 복제가 필요
d = copy.deepcopy(c) # 깊은 복제, 재귀적 복제
print(c,d)
#c[0] 객체와 d[0]객체는 같은ㅇ 객체인가?
print("c is d?", c is d)
print("c[0] is d[0]?", c[0] is d[0])
if __name__ == "__main__":
#func()
#symbol_table()
#object_id()
object_copy()
'2020 > Python' 카테고리의 다른 글
| 함수의 스코핑(Scope),가변인자, 고정인가, 키워드인자 (0) | 2019.11.20 |
|---|---|
| Python 흐름제어(조건문, 반복문) if, elif,else, while, for, 조건표현식 (0) | 2019.11.20 |
| Python 기초문제(3문제) (0) | 2019.11.19 |
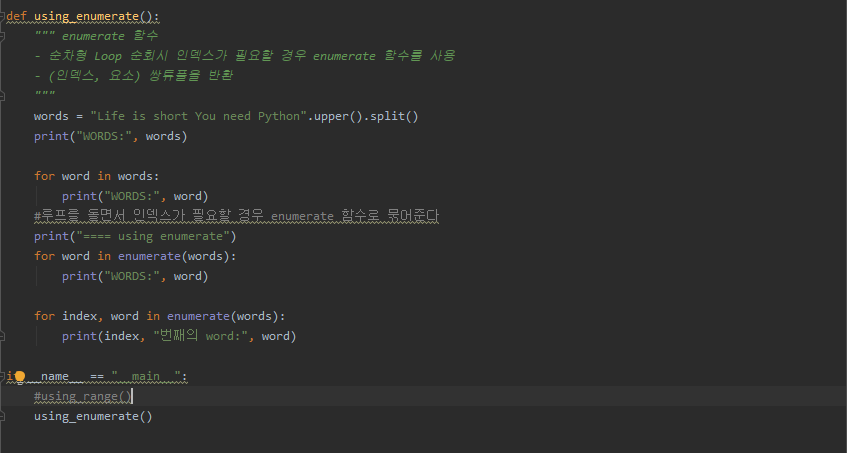
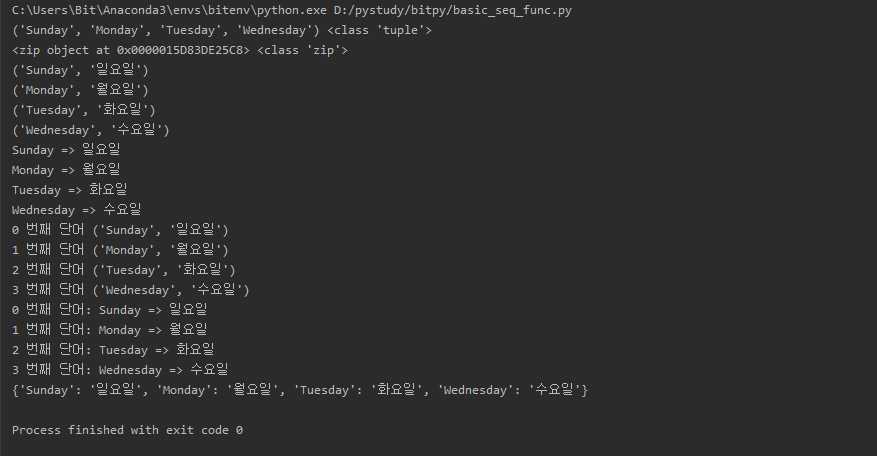
| Python 순차 자료형(Sequence) 내장 함수(range,enumerate,zip) (0) | 2019.11.19 |
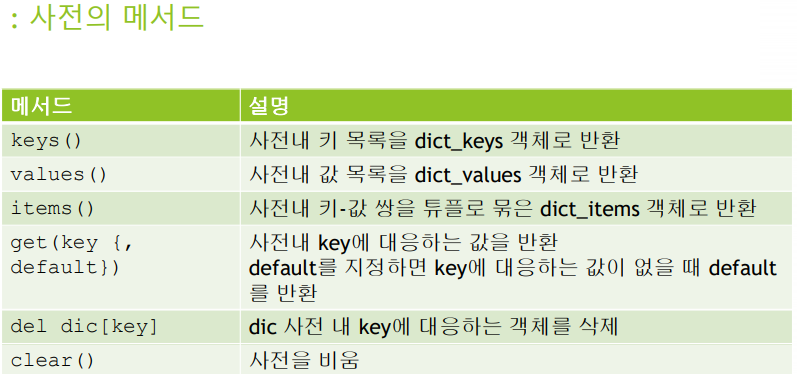
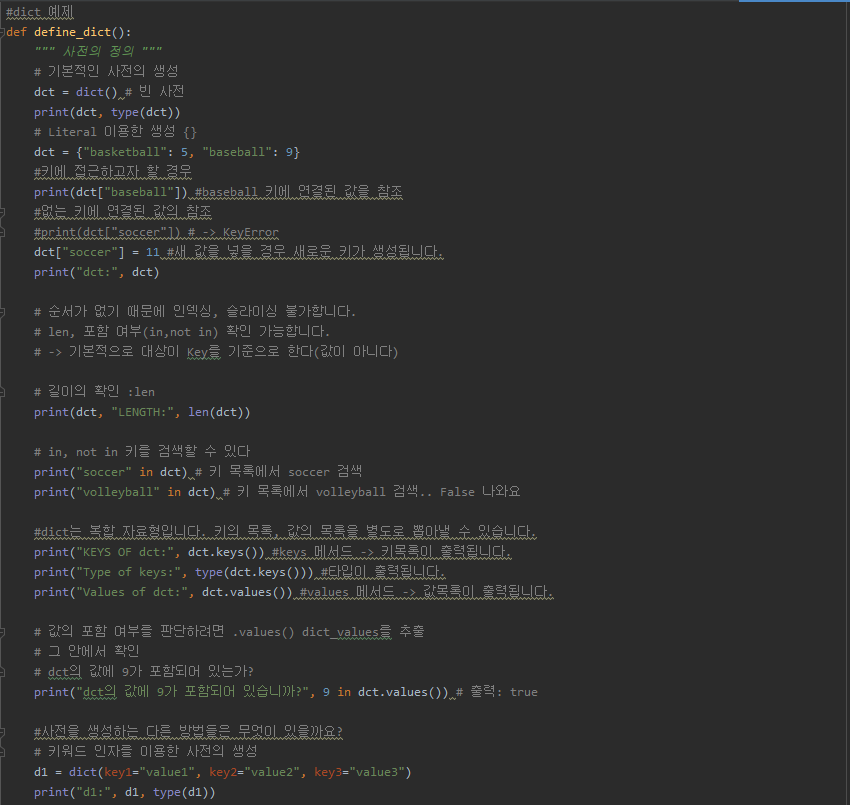
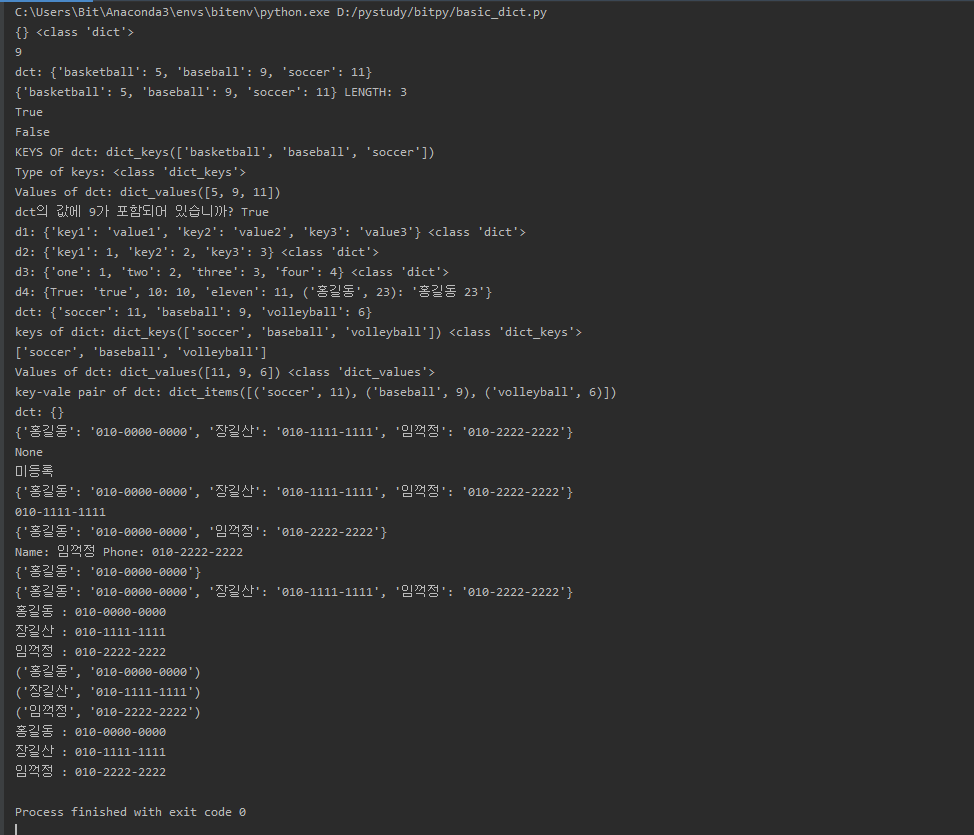
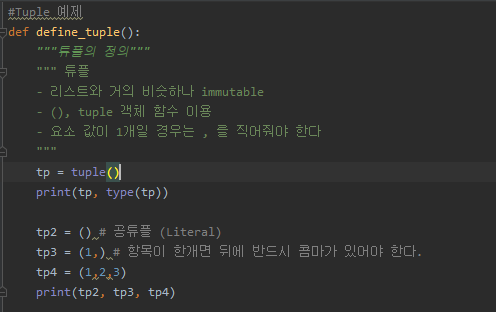
| Python 사전(dict) (0) | 2019.11.19 |

꽃꽂이하는개발자